


Database Crawling and Serving
Database Crawler Deprecation Notice
In GSA release 7.4, the on-board database crawler is deprecated. It will be removed in a future release. If you have configured on-board database crawling for your GSA, install and configure the Google Connector for Databases 4.0.4 or later instead. For more information, see “Deploying the Connector for Databases,” available from the Connector Documentation page.
Introduction
The following table lists the major sections in this chapter.
|
The relational databases that the Google Search Appliance can crawl |
|
|
How to configure a Google Search Appliance for database crawling and serving |
|
Supported Databases
Overview of Database Crawling and Serving
The following diagram provides an overview of the major database crawl and serve processes:
See the following sections in this document for descriptions of each major process. For an explanation of the symbols used in the diagram, refer to About the Diagrams in this Section.
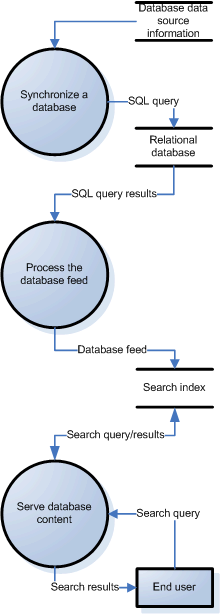
Synchronizing a Database
The process of crawling a database is called synchronizing a database. Full database synchronizations are always manual and you must start one by using the Content Sources > Databases page. The Google Search Appliance does not currently support scheduled database synchronization.
After you start database synchronization (see Starting Database Synchronization), the TableCrawler and TableServer use JDBC adapters to connect to the specified database. They connect by using information that you provide when you configure database crawling and serving (see Configuring Database Crawling and Serving).
Specifically, the TableCrawler sends the database the SQL query that you entered in the Crawl Query field, using the JDBC database client libraries.
The results are wrapped in Feed XML (eXtensible Markup Language) syntax (see The Feed XML and Stylesheet), and include a record for each row of the database crawl query results. This database feed file is presented to the Feeder system as soon as the crawl is complete.
To prevent the Google Search Appliance from deleting database content from the index when its PageRank™ is low and the index has reached its license limit, click the Lock documents checkbox under Create (see Providing Database Data Source Information).
Processing a Database Feed
Once synchronization is complete, the database feed is automatically uploaded to the search appliance for inclusion in the index. The crawl query (see Crawl Queries) is used to produce a feed description. All feeds, including database feeds, share the same namespace. Database source names should not match existing feed names.
Unique Generated URLs
Pages created from the database being indexed all have the form shown in the following example.
googledb://<database-hostname>/<DB_SOURCE_NAME>/
Therefore, you need to enter this pattern in Follow Patterns on the Content Sources > Web Crawl > Start and Block URLs page in the Admin Console. For more details see Setting the URL Patterns to Enable Database Crawl.
The Feeds connector generates a URL from either the Primary Key columns or from the URL column as specified in Serve URL field on the Content Sources > Databases page. A unique hash value is generated from the primary key to form part of the URL.
These generated URLs have the form shown in the following example.
http://<appliance_hostname>/db/<database-hostname>/<DB_SOURCE_NAME>/<result_of_hash>
Serving Database Content
Generating Search Results
Displaying Search Results
|
•
|
Generated on the search appliance (when Serve Query is used). The URLs are rewritten by the XSLT to be served through the search appliance by using the following format: http://<appliance_hostname>/db/<database-hostname>/<DB_SOURCE_NAME>/<result_of_hash>
|
|
•
|
Obtained from the database (when Serve URL Field is used).
|
The TableServer is not used if Serve URL Field is selected. Serve URL Field indicates the column in the database that contains a URL to display for each row, when the user clicks on the result of a search.
When Serve URL Field is selected, the database stylesheet is only used to format the database data for indexing and for the snippets. It is not used by the referenced URL from Serve URL Field.
Configuring Database Crawling and Serving
Before you can start database synchronization (see Starting Database Synchronization), you must configure database crawling and serving by performing the following tasks:
Providing Database Data Source Information
|
•
|
Crawl query (see Crawl Queries)—A SQL query for the database that returns all rows to be indexed
|
|
•
|
Serve query (see Serve Queries)—A SQL statement that returns a row from a table or joined tables which matches a search query.
|
|
•
|
Data Display/Usage (see The Feed XML and Stylesheet)—The stylesheet used to format the content of the Feed XML document
|
|
•
|
Advanced Settings (see Configuring Advanced Settings)—Incremental crawl query, BLOB fields
|
You provide database data source information by using the Create New Database Source section on the Content Sources > Databases page in the Admin Console. To navigate to this page, click Content Sources > Databases.
For complete information about the Create New Database Source section, click Admin Console Help > Content Sources > Databases in the Admin Console.
Crawl Queries
An SQL crawl query must be in the form shown in the following example.
SELECT <table.column> [, <table.column>, ...]
FROM <table> [, <table>, ...
[WHERE some_condition_or_join]
Serve Queries
A serve query displays result data using the ’?’ in the WHERE clause to allow for particular row selection and display. The Primary Key Fields must provide the column names for the field to substitute with the ’?’.
Crawl and Serve Query Examples
This section shows example crawl and serve queries for an employee database with these fields:
employee_id, first_name, last_name, email, dept
The following example shows the crawl query.
SELECT employee_id, first_name, last_name, email, dept
FROM employee
The following example shows the serve query.
SELECT employee_id, first_name, last_name, email, dept
FROM employee
WHERE employee_id = ?
The Primary Key field for this case must be employee_id. The ’?’ signifies that this value is provided at serve time, from the search result that the user clicks.
For a table with multiple column Primary Keys, if the combination of employee_id, dept is unique, you can use multiple bind variables. The crawl query for this example is the same as shown in this section. The following example shows the serve query.
SELECT employee_id, first_name, last_name, email, dept
FROM employee
WHERE employee_id = ? AND dept = ?
|
•
|
The column names specified in the WHERE clause must be included in the same order in the Primary Key Fields.
|
The Feed XML and Stylesheet
You specify a stylesheet for formatting the content of the Feed XML document by using the stylesheet specified in the Data Display/Usage section of the Content Sources > Databases page in the Admin Console. This stylesheet defines the formatting used between each record.
You can use the default database stylesheet, or upload your own. To view the default database stylesheet, dbdefault.xsl, download it from this link: https://support.google.com/gsa/answer/6069358. You can make changes to it, and then upload it by using the Upload stylesheet selection on the Content Sources > Databases page.
Each row returned by the database is represented by a unique URL in the appliance index.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE gsafeed SYSTEM "http://ent1:7800/gsafeed.dtd">
<gsafeed>
<header>
<datasource>DB_SOURCE_NAME</datasource>
<feedtype>full</feedtype>
</header>
<group>
<record url="googledb://mydb.mycompany.com/DB_SOURCE_NAME/azE9MSwwOTk4T0U3NTAwNisrKysrKysrKyZrMj0yLDA"
action="add" mimetype="text/html" lock="true">
<content><![CDATA[<html>
<head>
<META http-equiv="Content-Type" content="text/html;
charset=UTF-8">
<title>Default Page</title>
</head>
<body style="font-family: arial, helvetica, sans-serif;">
<H2 align="center">Database Result</H2>
<table cellpadding="3" cellspacing="0" align="center"
width="100%" border="0">
<tr>
<th style="border-bottom: #ffcc00 1px solid;" align="left">
DOC_ID_COLUMN
</th>
<th style="border-bottom: #ffcc00 1px solid;" align="left">
SECOND_COLUMN_NAME
</th>
<th style="border-bottom: #ffcc00 1px solid;" align="left">
THIRD_COLUMN_NAME
</th>
</tr>
<tr valign="top" bgcolor="white">
<td><font size="-1">2</font></td>
<td><font size="-1">Second column content data.</font></td>
<td><font size="-1">Third column content data.</font></td>
</tr>
</table>
</body>
</html>
]]></content>
</record>
</group>
</gsafeed>
<head>
<title>Default Page</title>
<xsl:for-each select="/database/table/table_rec/*">
<meta>
<xsl:attribute name="name">
<xsl:value-of select="name(.)"/>
</xsl:attribute>
<xsl:attribute name="content">
<xsl:value-of select="."/>
</xsl:attribute>
</meta>
</xsl:for-each>
</head>
Configuring Advanced Settings
SELECT ... WHERE last_modified_time > ? The ? will hold the last successful crawl time from the appliance. If you do not use the ? character, the query will fail. YYYY-MM-DD HH:MM:SS and will be in GMT. Also the column must have a date data type. SELECT ..., action WHERE last_modification_time > ?
|
|
Setting URL Patterns to Enable Database Crawl
When you set up a database crawl you need to include entries in the Follow Patterns fields on the Content Sources > Web Crawl > Start and Block URLs page of the Admin Console.
To include all database feeds, use the following crawl pattern:
^googledb://
To include a specific database feed, use the following crawl pattern:
^googledb://<database_host_name>/<database_source_name>/
If your data source contains a URL column with URLs that point to your own website, add those URL patterns under Follow Patterns on the Content Sources > Web Crawl > Start and Block URLs page.
For complete information about the Content Sources > Web Crawl > Start and Block URLs page, click Admin Console Help > Content Sources > Web Crawl > Start and Block URLs in the Admin Console.
For more information about URL patterns, see Constructing URL Patterns.
Starting Database Synchronization
After you configure database crawling and serving (see Configuring Database Crawling and Serving), you can start synchronizing a database by using the Content Sources > Databases page in the Admin Console.
|
1.
|
Click Content Sources > Databases.
|
|
2.
|
In the Current Databases section of the page, click the Sync link next to the database that you want to synchronize.
|
After you click Sync, the link label changes to Sync’ing, which indicates that the database crawl is in process. When the crawl completes, Sync’ing no longer appears. However, to see the updated status for a database synchronization, you must refresh the Content Sources > Databases page. To refresh the page, navigate to another page in the Admin Console then navigate back to the Content Sources > Databases page.
You can also use the Current Databases section of the Content Sources > Databases page to edit database data source information for a database, delete a database, or view log information for a database.
For complete information about the Current Databases section, click Admin Console Help > Content Sources > Databases in the Admin Console.
Monitoring a Feed
You can monitor the progress of a database feed by using the Content Sources > Feeds page in the Admin Console. This page shows all feed status, including the automatically-entered database feed. When a feed process successfully finishes, it is marked completed on the page.
For complete information about the Content Sources > Feeds page, click Admin Console Help > Content Sources > Feeds in the Admin Console.
For more information about feeds, refer to the Feeds Protocol Developer’s Guide.
Troubleshooting
Verify that a database process is listening on the host and port that has been specified on the Content Sources > Databases page. For example, the default port for MySQL is 3306. Run the following command and verify that you get a connection. Be sure to test this from a computer on the same subnet as the appliance.
telnet <dbhostname> 3306
Verify the remote database connection
mysql -u<username> -p<password> -h<dbhostname> <database>
In this example, the MySQL client must be available on the computer used.
Look at the logs on the database server to see whether there was a successful connection.
Check for a database URL in the Follow and Crawl Patterns
Ensure that a suitable follow and crawl URL pattern for the database is entered on the Content Sources > Web Crawl > Start and Block URLs page in the Admin Console. If there is no suitable pattern:
|
1.
|
Enter the following pattern in Follow Patterns:
|
^googledb://<appliance_ip_address>/db/
|
2.
|
Click the Save button to save your changes.
|
Check the Serve Query or Serve URL
On the Content Sources > Databases page, make sure there is either a valid entry in either Serve Query or Serve URL Field.
Verify a known-working crawl query
Verify that a known-working crawl query, which produces a small number of results, works correctly.
Run a tcpdump on the traffic between the appliance and the database server on the specified port when you do a sync. Compare to a tcpdump from a successful connection.
If the sync has completed successfully, troubleshoot the feed. For information about troubleshooting feeds, refer to the Feeds Protocol Developer’s Guide.
Frequently Asked Questions
Q: Can multiple databases be synchronized at one time?
Q: When will the database be resynchronized?
A: A database is only synchronized fully when you click the Sync link on the Content Sources > Databases page in the Admin Console. Incremental synchronizations are a more efficient mechanism for updating the index for large query result sets which only change partially. Neither incremental nor full database syncs are scheduled automatically.
Q: Is there a way to schedule a database crawl?
A: There is currently no way to schedule a database crawl. It can be synchronized manually from the Content Sources > Databases page.
Q: Can a sync be stopped once it’s in progress?
A: There is currently no way to stop a database synchronization once it is started.
Q: How can I tell the status of the sync?
A: On the Content Sources > Databases page, the Sync link under Current Databases reads Sync’ing when the link is clicked. Go to a different page in the Admin Console and returning to the Content Sources > Databases page to refresh and update the status. After a successful database synchronization, a feed appears on the Content Sources > Feeds page.
Q: Sun defines several types of JDBC adapters. Which ones can be used?
A: The Google Search Appliance supports the Java to DB direct adapter types.
Q: What SQL is supported in the database configuration page? SQL99? ANSI SQL?
A: This is dependent on the JDBC adapters used to connect with your database.
Q: Can the list of JDBC adapters used be updated?
A: Currently the Google Search Appliance does not support modification of the JDBC adapter list.
Q: Is the database connection secure?
Q: Can the Google Search Appliance crawl the access information from the database?
A: The Google Search Appliance does not support evaluation of database ACLs.
Q: Can the Fully Qualified Domain Name be used for the crawl patterns?
A: No. Currently, the crawl patterns must specify the appliance using its IP address.
Q: Is there a DTD for the XML produced from the database for providing a custom stylesheet?
To use the identity_transform.xsl and see the raw XML:
|
2.
|
Provide information about the database using the Create New Database Source section of the Content Sources > Databases page.
|
|
3.
|
Choose identity_transform.xsl after clicking Upload Stylesheet.
|
|
4.
|
|
5.
|
Click Create.
|
|
6.
|
Click Sync for the database.
|
A: When you click the Sync link on the Content Sources > Databases page in the Admin Console for a database source name, the old contents in the index are invalidated.